Um banco de dados não relacional é qualquer banco de dados que não segue o modelo relacional fornecido pelos sistemas tradicionais de gerenciamento de bancos de dados relacionais (SGBDR). Esta categoria de bancos de dados, é também conhecida como banco de dados NoSQL.
O termo NoSql, significa “Not Only SQL” ou “Não Apenas SQL”, o que pode gerar um pouco de confusão.
As bases de dados relacionais dependem de tabelas, colunas, linhas ou esquemas para organizar e recuperar dados. Em contraste, os bancos de dados NoSQL não se baseiam nestas estruturas e utilizam modelos de dados mais flexíveis.
Os bancos de dados NoSQL utilizam uma variedade de modelos de dados para acessar e gerenciar dados. Estes tipos de bancos de dados são otimizados especificamente para aplicações que requerem grande volume de dados, baixa latência e para modelos de dados flexíveis, o que é obtido através do relaxamento de algumas das restrições de consistência de dados.
Um equívoco muito comum é pensar que bancos de dados NoSQL ou bancos de dados não-relacionais não armazenam bem dados que tenham algum tipo de relacionamento.
Os bancos de dados NoSQL podem armazenar dados com relacionamento – eles apenas os armazenam de forma diferente dos bancos de dados relacionais. De fato, quando comparados com bancos de dados SQL, muitos acham que modelar dados com relacionamento em bancos de dados NoSQL é mais fácil do que em bancos de dados SQL, porque os dados relacionados não precisam ser divididos entre tabelas.
Os modelos de dados NoSQL permitem que os dados que tenham alguma relação sejam aninhados dentro de uma única estrutura de dados.
Os primeiros bancos de dados NoSQL desenvolvidos primariamente para aplicações web e em nuvem tendiam a focar em características muito específicas do gerenciamento de dados. Dentre elas a capacidade de processar volumes grandes de dados e distribuir rapidamente esses dados através de clusters.
Os desenvolvedores que implementaram sistemas web e na nuvem também procuraram criar um esquema de dados flexível — ou esquema nenhum — para permitir mudanças rápidas em aplicações que eram continuamente atualizadas.
Existem quatro grandes tipos de NoSQL: Key-value stores, Graph stores, Column stores, e Document stores. Cada tipo resolve um problema que muitas vezes não pode ser resolvido com bancos de dados relacionais. As implementações reais são freqüentemente combinações destas categorias.
OrientDB, por exemplo, é um banco de dados multi-modelo, combinando dois tipos de NoSQL, ele é uma base de dados do tipo Graph store onde cada nó é um Document.
Alguns dos bancos de dados NoSQL mais populares são MongoDB, Apache Cassandra, Redis, Couchbase e Apache HBase.
Um banco de dados do tipo key-value (valores-chave), associa um valor (que pode ser qualquer coisa, desde um número ou simples string, até um objeto complexo) com uma chave, que é usada para manter o controle do objeto.
Em sua forma mais simples, um banco de dados não relacional do tipo valores-chave é como um objeto de dictionary/array/map como os existentes na maioria das linguagens de programação, mas que é armazenado de forma persistente e administrado por um Sistema de Gerenciamento de Banco de Dados (SGBD).

As bases de dados de valores-chave utilizam estruturas de índice compactas e eficientes para ser capazes de localizar um valor de forma rápida e confiável por sua chave, tornando-os ideais para sistemas que precisam ser capazes de encontrar e recuperar dados em períodos de tempo constantes.
Redis Sendo um dos mais populares
Um base de dados do tipo document gerencia um conjunto de campos com chaves e valores em uma entidade referida como documento. Estes dados armazenam normalmente dados na forma de documentos JSON.
Cada campo referencia um valor que pode ser um expresso de várias maneiras, como um número, um objeto, array, uma string ou um outro documento. Os dados nos campos de um documento podem ser codificados de várias maneiras, incluindo XML, YAML, JSON, BSON, ou até mesmo armazenados como texto simples.
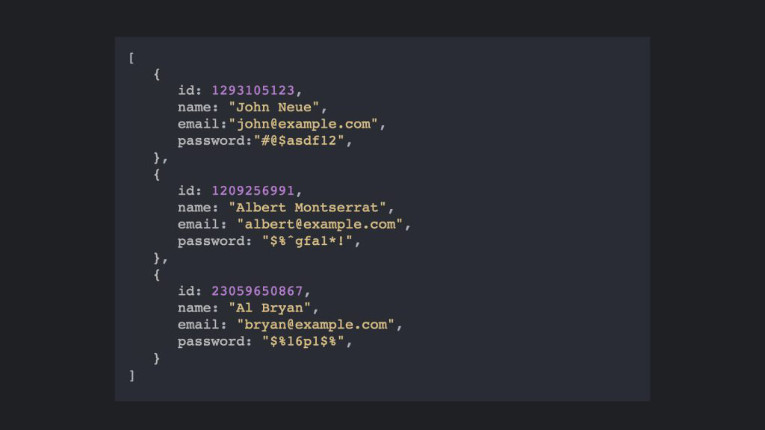
Normalmente, um documento contém os dados completos de uma entidade. Os itens que constituem uma entidade são específicos da aplicação. Por exemplo, uma entidade pode conter os detalhes de um cliente, um pedido, ou uma combinação de ambos.
Um único documento poderia conter informações que estariam espalhadas por várias tabelas relacionais em um sistema de gerenciamento de banco de dados relacional (RDBMS). A base de dados do tipo documentos não exige que todos os documentos tenham a mesma estrutura, esta abordagem proporciona uma grande flexibilidade.
O seu aplicativo pode recuperar documentos usando uma chave única do documento que muitas vezes tem um formato hash. O banco de dados não relacional do tipo documento, criam a chave automaticamente, outros permitem especificar um atributo do documento a ser usado como chave. O aplicativo também pode consultar documentos com base no valor de um ou mais campos.
Muitas bases de dados dot tipo documento suportam atualizações locais, ou seja permitem que uma aplicação modifique os valores de campos específicos em um documento sem reescrever o documento inteiro. Operações de leitura e escrita sobre vários campos em um único documento são tipicamente atômicas.
MongoDB como sendo um dos mais populares nessa categoria.
O banco de dados do tipo Coluna, também conhecido como “familia de colunas”, utiliza colunas para armazenar dados ao invés de linhas como no modelo relacional. Em sua forma mais simples, esse formato pode parecer muito semelhante a um banco de dados relacional, pelo menos conceitualmente. O verdadeiro poder de um banco de dados coluna-família reside em sua abordagem desnormalizada da estruturação de dados esparsos.
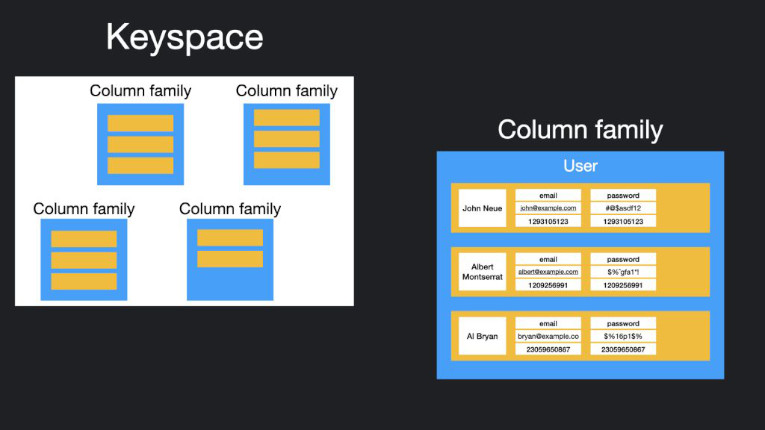
Você pode pensar nesse modelo como um armazenamento de dados tabulares com linhas e colunas, mas as colunas são divididas em grupos conhecidos como famílias de colunas.
Cada família de colunas contém um conjunto de colunas que são logicamente relacionadas e são normalmente recuperadas ou manipuladas como uma única unidade. Outros dados que são acessados separadamente podem ser armazenados em famílias de colunas separadas.
Dentro de uma família de colunas, novas colunas podem ser adicionadas dinamicamente e linhas podem ser esparsas (ou seja, uma linha não precisa ter um valor para cada coluna).
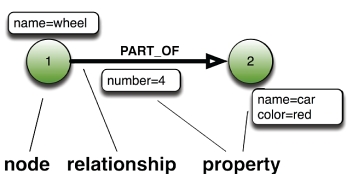
Um banco de dados do tipo graph gerencia dois tipos de informações, nós e arestas. Os nós representam entidades, e as arestas especificam as relações entre estas entidades. Ambos, nós e arestas, podem ter propriedades que fornecem informações sobre o nó ou aresta, semelhantes as colunas em uma tabela. As arestas também podem ter uma direção indicando a natureza da relação.
O objetivo de um armazenamento de dados do tipo graph é permitir que uma aplicação execute consultas que atravessam a rede de nós e arestas de forma eficiente, e que permita analisar as relações entre entidades.
Em contraste com os bancos de dados relacionais e NoSQL, os bancos de dados do tipo graph armazenam as relações de dados como relacionamentos. Este armazenamento explícito de dados de relacionamento significa menos desconexões entre seu esquema e seu banco de dados real.
Na verdade, a flexibilidade do modelo de grafos permite adicionar novos nós e relacionamentos sem comprometer sua rede existente ou migrar seus dados de forma demorada. Todos os seus dados e relacionamentos originais permanecem intactos.
Cada tipo específico de banco de dados NoSQL tem pontos fortes diferentes, mas todos compartilham características fundamentais que lhes permitem:
Em resumo, a diferença entre bancos de dados relacionais e bancos de dados NoSQL são desempenho, disponibilidade e escalabilidade.
hi man,how are you?
Deixe um comentário