By the end of this decade, our digital data universe will grow from 4.4 zettabytes today to about 44 zettabytes, or 44 trillion gigabytes.
OK, so we know you’re here to weigh the technical differences between the relational and non-relational databases. But before we dive in, we need to define some important details. You need to determine what priority scalability represents for your particular model.
To make your data model as accurate as possible, you need to ask the right questions. Otherwise, your solution may not be the most appropriate for your problem. If you already have this well defined, go ahead.
A relational database is a digital database based on the relational data model as proposed by E. F. Codd in 1970, an intuitive and direct way to represent data in tables. Relational databases store and provide access to data points that are related to each other.
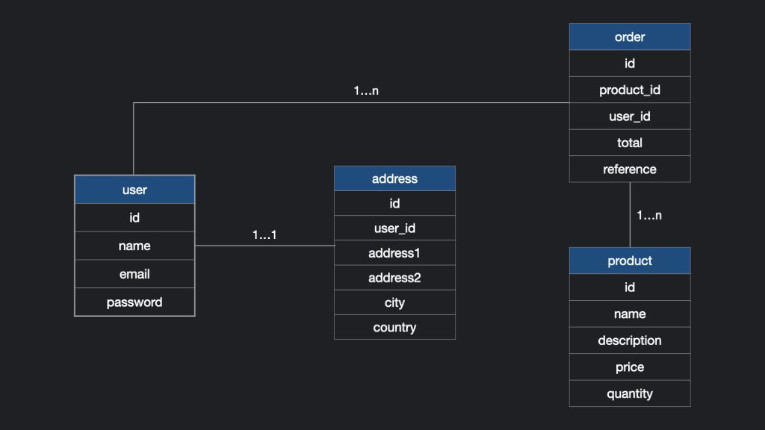
In a relational database, each table row is a record with a unique identification called a primary key. The table columns contain the data attributes, and each record usually has a value for each attribute, making it easier to establish the relationships between the data. In this example below the Primary Key is the id.
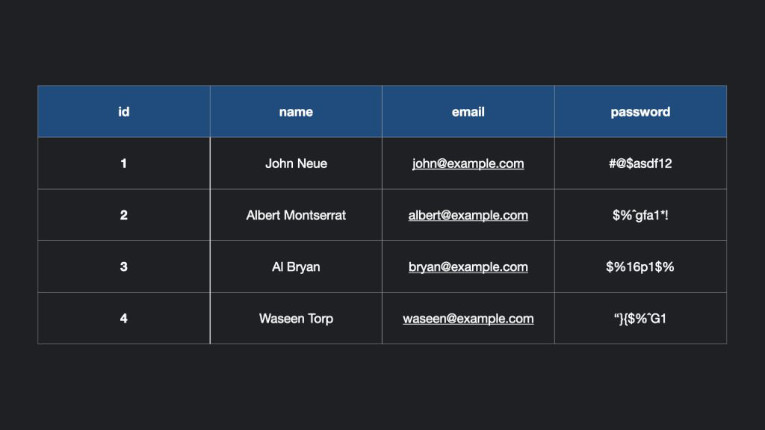
There are several systems you can use to manage relational databases, they are known as Relational Database Management Systems (DBMS). The most popular among them is MySQL, but we also have other options like Oracle Database, Microsoft SQL Server, and IBM DB2.
The vast majority of RDBMS offer the option to use SQL (Structured Query Language) for database query and maintenance.
One of the advantages of a relational database is that once you have your data kept in clearly defined tables you can connect or relate the data between different tables. In order to identify these relationships, you need to examine the data and have an understanding of the business rules that apply to the data and tables.
When creating relationships, you always work with two tables at a time. One table is called the main table or parent table and the other is the related table or child table.
The three types of relationships you will find in the relational databases are, one-to-one, one-to-many, and many-to-many. The relationships are described below.
A non-relational database is any database that does not follow the relational model provided by traditional relational database management systems (RDBMS). This category of databases is also known as NoSQL databases.
The most popular being MongoDB, DocumentDB, Cassandra, Couchbase, HBase, Redis, and Neo4j. These databases are generally grouped into four categories: Key-value stores, Graph stores, Column stores, and Document stores.
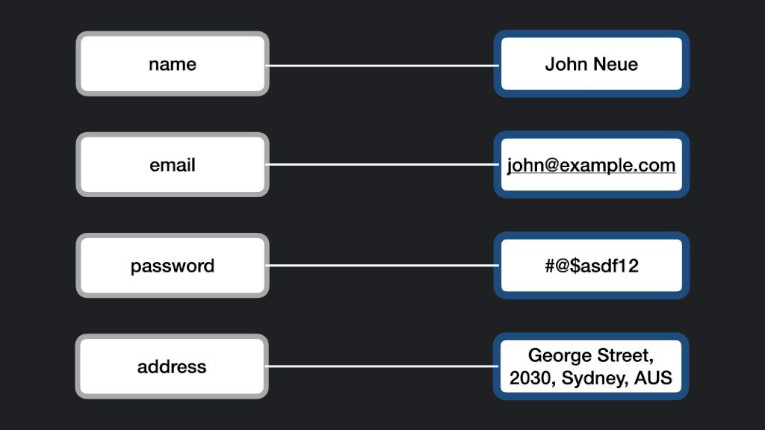
As the name suggests, in a key-value database, the data is represented as a collection of pairs of key values. They are also known as associative arrays, organized in rows.
These databases store the data as a hash table with a unique key and pointer to a particular data item. Similar to traditional hash tables, this type of database allows the storage and retrieval of data using keys.
Key-value databases are used whenever data is queried by precise parameters and need to be recovered quickly.
Although key-value databases can handle a large amount of data, they are designed for a high level (low depth) view of the data. Graph databases can maintain a minimum storage size, even with a greater depth of data than other types of databases.

The graph-type NoSQL database was specially developed to handle very large sets of structured, semi-structured, or unstructured data. It helps organizations access, integrate, and analyze data from various sources.
Widely used when it is necessary to analyze data from social networks, for example.
A column data storage, also known as DBMS in column, uses columns to store data instead of rows as in the relational model. Both row-based and column-based DBMS use SQL as the query language, but column-based DBMS can offer better performance.
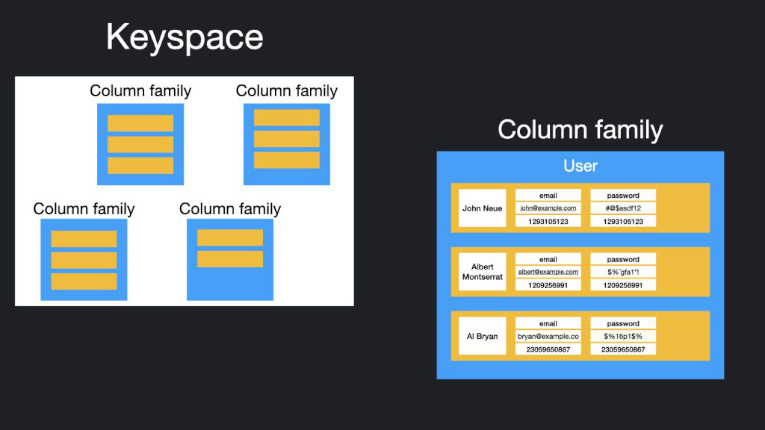
Column store databases use a concept called keyspace. A keyspace is like a schema in the relational model. The keyspace contains all column families (such as tables in the relational model), which contain rows, which contain columns.
The document store type database, also called document oriented DBMS, is characterized by its data organization without schemas.
This means that the records do not need to have a uniform structure, that is, different records can have different columns. The value types can be different for each record, the columns can have more than one value (arrays), and the records can have a nested structure.
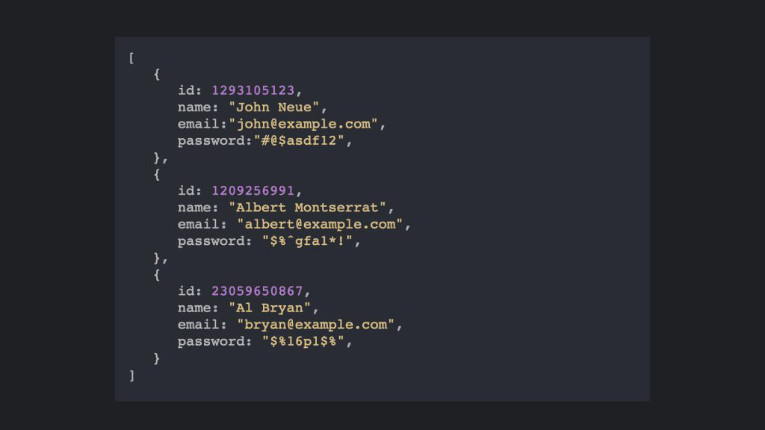
Documents are usually stored in a structure similar to JSON, which makes life easier for the programmer, and JSON is one of the most common data structures, especially working with Javascript.
Relational databases like MySQL, PostgreSQL and SQLite3 represent and store data in tables and queues. Non-relational databases like MongoDB represent data in JSON document collections.
Relational databases use Structured Query Language (SQL), making them a good choice for applications that involve the management of various transactions. The structure of a relational database allows linking information from different tables through the use of foreign keys (or indexes).
Se você estiver lidando com uma quantidade fenomenal de dados, a complexidade do banco de dados relacional e das queries necessárias também vai crescer na mesma proporção. Nessa situação, talvez você precise considerar a possibilidade de utilizar um base de dados não relacional. Uma base de dados não relacional apenas armazena dados sem uma mecânica explícita e estruturada para vincular dados de diferentes tabelas uns aos outros.
If you are dealing with a phenomenal amount of data, the complexity of the relational database and the required queries will also grow in the same proportion. In this situation, you may need to consider using a non-relational database. A non-relational database can store data without an explicit and structured mechanics to link data from different tables to each other.
Although relational databases are great, they come with trade-offs. One of them is ORM Impedance Mismatching, because relational databases were not initially created with OOP languages in mind. The best way to avoid this issue is to create your database schema with referenced integrity. Therefore, when using a relational database with OOP (such as Ruby or Java), you have to think about how to configure your primary and foreign keys, the use of constraints (including deletion and cascading), and how to write your migrations.
In non-relational databases like MongoDB, there are no joins like in relational databases. This means you need to perform multiple queries and join the data manually within your code.
Since Mongo does not automatically treat the operations as transactions in the same way as a relational database, you must choose to create a transaction and then check it, commit, or rollback manually.
My suggestion is, analyze the data you will store. Ask the right questions to find out what data model you’ll need. Choosing the programming language to write your application and using a specific database will get your application on the right track.
If you like the article, be sure to comment and share. And so you don’t miss any news here, subscribe to the newsletter and receive exclusive content every week! See you next time!
Thanks for the good article, I hope you continue to work as well.
of course like your web-site but you need to check the spelling on several of your posts. A number of them are rife with spelling issues and I find it very bothersome to tell the truth nevertheless I’ll definitely come back again.
Gostei tanto"
Thanks for another informative website. Where else could I get that kind of info written in such a perfect way? I've a project that I am just now working on, and I've been on the look out for such info.
Leave a Reply